Azure Data Factory Pre and Post Deployment for Octopus Deploy
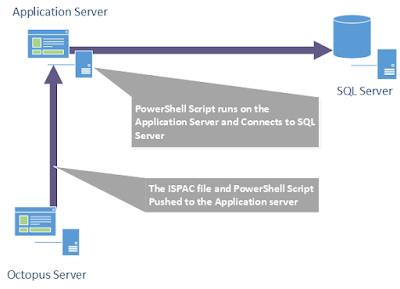
This post covers how I solve a deployment and maintenance problem with Azure Data Factory (ADF). The problem was ensuring that the ADF instance only contains the active datasets, pipelines, dataflows and triggers. As mentioned in a previous post, my current company has tight security controls, which prevents us from linking our ADF instance to our git repository; our deployment method uses Octopus Deploy with a mixture of ARM template and Terraform. I use the Terraform to create the ADF instance and then ARM template for the ADF objects, like datasets, pipelines and dataflows, which causes the maintenance problem because the ARM templates deployment process does not delete objects that don’t exist in the ARM template. We found this out after we did a recent significant change to our ADF code and found many unused objects still in our ADF instance. I didn’t want to leave the unused objects for the following reasons: It would make it hard for other developers to understand what ADF ob...