Automation database deployment with refactored objects
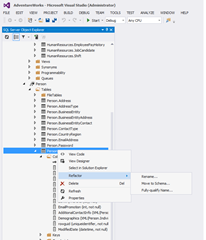
While automating the deployment for my SQL Server Data Tools (SSDT) projects, as mentioned in a previous post: Automating SQL Server Database Projects Deployment , I found it important to create / maintain the projects refactor logs. This is because SSDT / DAC framework uses the model driven deployment method, which works by comparing the model with the target database to create / execute a delta script for updating the database to match the model. A problem with is method is miss identifying objects which have been renamed or transferred to a new schema. For code objects like: store procedures, functions, views etc. this would be more of a nuisance as the database will contain redundant code. This would happen if the deployment option DropObjectsNotInSource is not set to true. This would make it harder to maintain the database and may cause future deployments to fail if schema binding is involved. However for tables or columns, again depending on deployment opti...