A Business Intelligence project ALM's

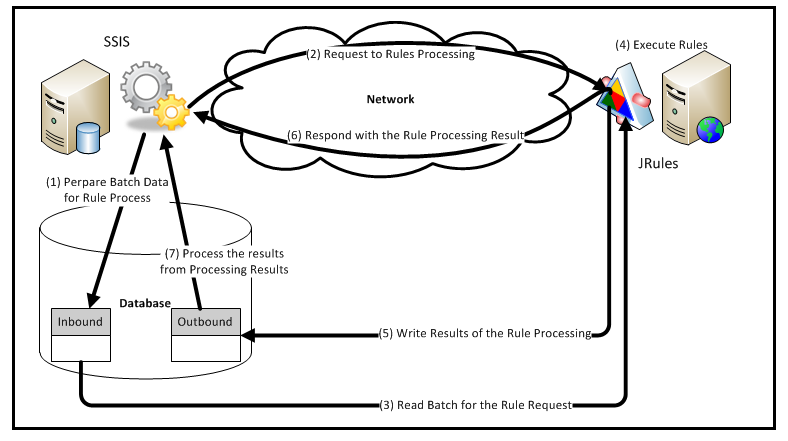
Table of Contents 1 Introduction. 2 Automation process components 2.1 The Build. 2.2 The Deployment script. 2.3 Automated deployment and execution. 3 Visual studio tips. 3.1 Reducing unresolve reference errors. 3.2 Composite Projects. 4 Resources. 1 Introduction As I have mentioned in previous posts I have been working on a data warehouse project. One of my main roles in this project was to work on the build, deployment and development processes. Within this post, I would like to show how I, with help from my colleagues, was able to automate a build, deployment and execute the data warehouse code. The reason for developing this automation was to try and find problems before we released to user acceptance testing (UAT). Once this automation started running it did capture errors. One error in particular, which would only appeared in release, was missing permissions. As the developers and the testing team all have different eleva